|
Data-driven approaches for autonomous driving (AD) have been widely adopted in the past decade but are confronted with dataset bias and uninterpretability.
Inspired by the knowledge-driven nature of human driving, recent approaches explore the potential of large language models (LLMs) to improve understanding and decision-making in traffic scenarios.
They find that the pretrain-finetune paradigm of LLMs on downstream data with the Chain-of-Thought (CoT) reasoning process can enhance explainability and scene understanding.
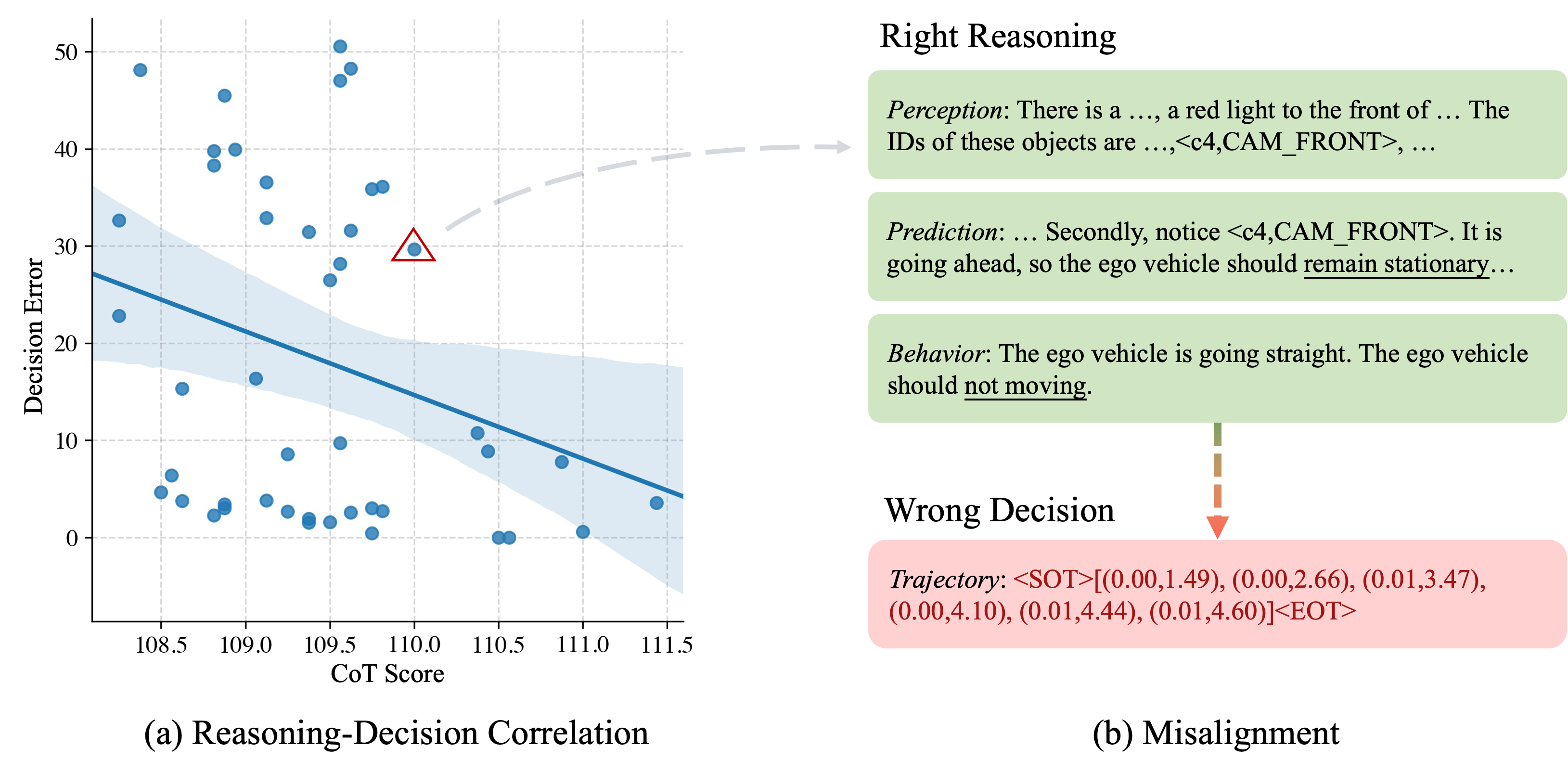
However, such a popular strategy proves to suffer from the notorious problems of misalignment between the crafted CoTs against the consequent decision-making, which remains untouched by previous LLM-based AD methods.
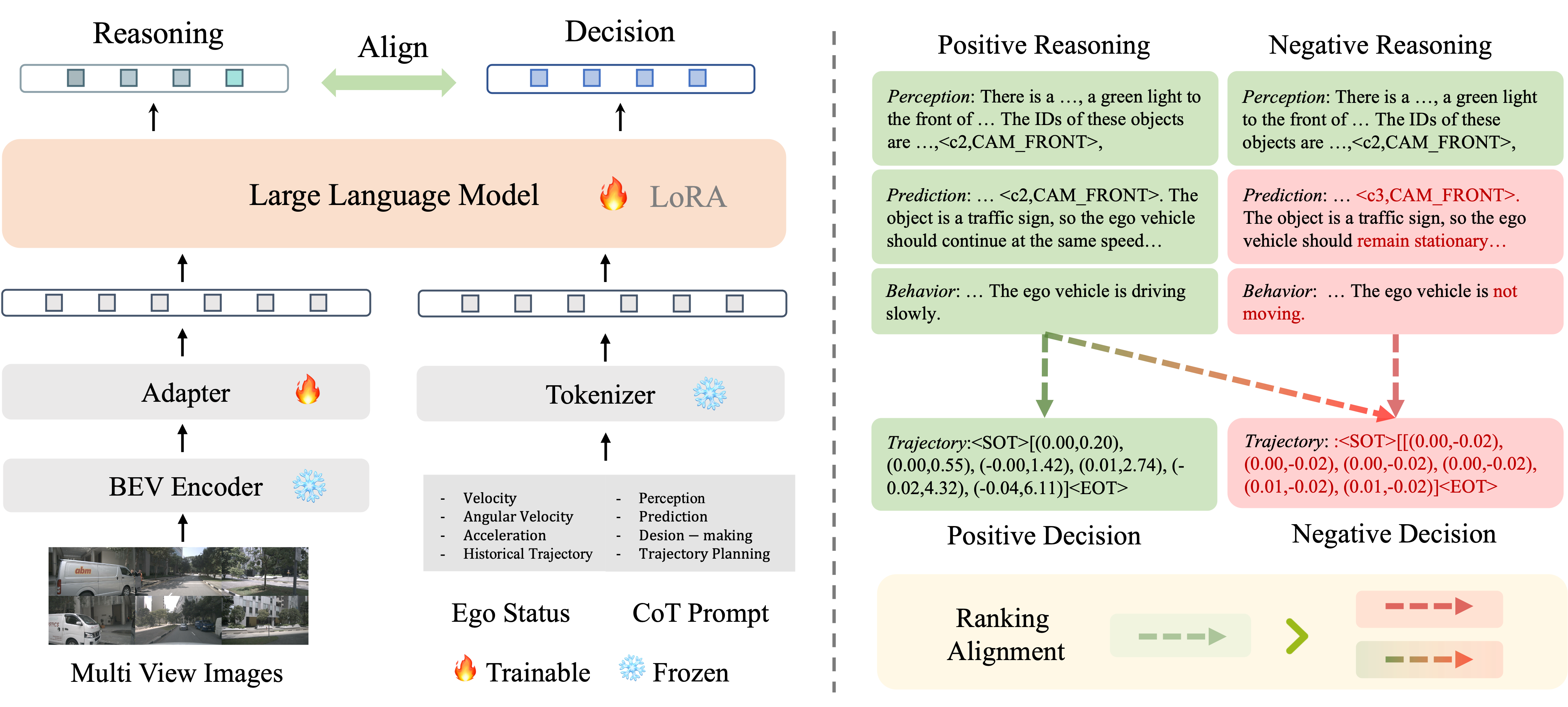
To address this problem, we motivate an end-to-end decisionmaking model based on multimodality-augmented LLM, which simultaneously executes CoT reasoning and carries out planning results.
Furthermore, we propose a reasoning-decision alignment constraint between the paired CoTs and planning results, imposing the correspondence between reasoning and decision-making.
Moreover, we redesign the CoTs to enable the model to comprehend complex scenarios and enhance decisionmaking performance.
We dub our proposed large language planners with reasoning-decision alignment as RDA-Driver.
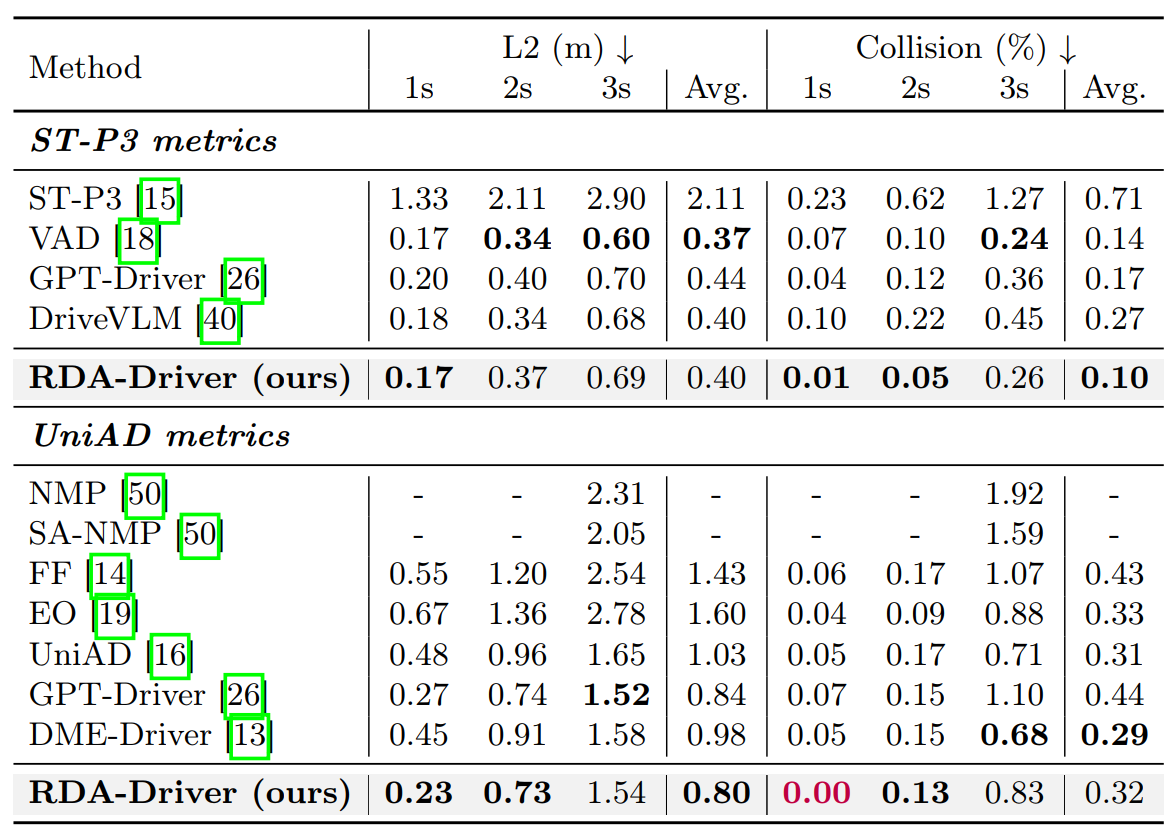
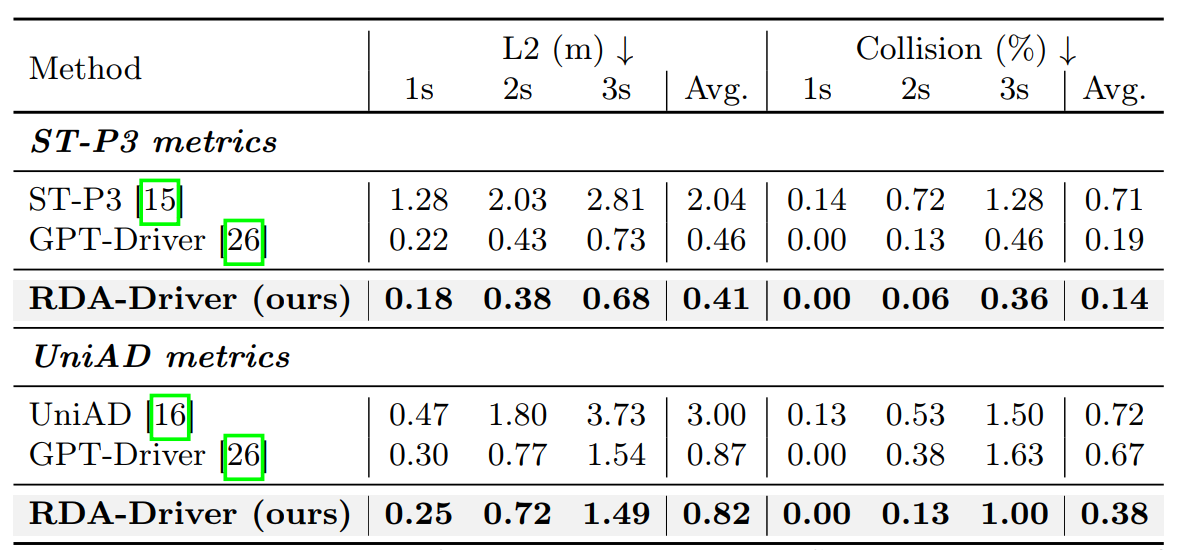
Experimental evaluations on the nuScenes and DriveLM-nuScenes benchmarks demonstrate the effectiveness of our RDA-Driver in enhancing the performance of endto-end AD systems.
Specifically, our RDA-Driver achieves state-of-theart planning performance on the nuScenes dataset with 0.80 L2 error and 0.32 collision rate, and also achieves leading results on challenging DriveLM-nuScenes benchmarks with 0.82 L2 error and 0.38 collision rate.
|